

GraphQL context (Graph query language)
1. Giới thiệu
GraphQL là một công nghệ mã nguồn mở (Server side) mà cho phép có thể thay thế REST API truyền thống. Công nghệ này được phát triển bởi Facebook và được sử dụng rộng rãi bởi nhiều phần mềm nổi tiếng (Air Bnb, Twitter..v.v)
Trước khi bắt đầu với việc tìm hiểu về GraphQL thì ta sẽ tìm hiểu sơ vấn đề mà các kĩ sư ở Facebook gặp phải và tại sao họ lại tạo ra công nghệ này ??
Đầu tiên , phải nói rằng trước khi có GraphQL , facebook cũng sử dụng REST API như bao project trước đây. Tuy nhiên vấn đề dần nảy sinh khi hệ sinh thái facebook ngày càng phức tạp. Họ có hàng tá các client truy cập kho dữ liệu (Web, mobile web, android app, ios app, v.v..) . Và vấn đề với REST API bắt đầu phát sinh
a) Vấn đề về Network Performance
Giả sử bạn có dữ liệu người dùng ở back-end với tên, họ, email và 10 trường khác. Ở Client, bạn chỉ cần một vài trường trong số đó.
Thực hiện REST call /users nó trả về cho bạn tất cả các trường của user, và client chỉ sử dụng những gì nó cần. Rõ ràng có một số dữ liệu bị thừa, và đặc biệt khi client là ở dạng mobile.
GraphQL mặc định fetch dữ liệu nhỏ nhất có thể. Nếu bạn chỉ cần tên và họ của user, bạn chỉ cần chỉ định nó trong truy vấn.
Query:
query {
users {
firstname
lastname
}
}
Result
{
"data": {
"users": [
{
"firstname": "John",
"lastname": "Doe"
},
{
"firstname": "Alicia",
"lastname": "Smith"
}
]
}
}
Nếu chúng ta muốn lấy thêm email, thì thêm "email" bên dưới "lastname".
Một số back-end REST cung cấp tùy chọn như /users? fields = firstname, lastname để trả về các partial resources ( Google khuyến cáo). Tuy nhiên, nó không được implement theo mặc định, và nó làm cho yêu cầu khó đọc hơn, đặc biệt là khi bạn ném vào các query parameters khác:
&status=active để filter các active user
&sort=createdAat để sắp xếp user dựa theo thời gian tạo
&sortDirection=desc vì rõ ràng là bạn cần nó
&include=projects để include các project của user
Các query parameters này là các bản vá được thêm vào REST API để bắt chước một ngôn ngữ truy vấn. GraphQL hơn hết tất cả các ngôn ngữ truy vấn, nó làm cho request ngắn gọn và chính xác ngay từ đầu.
b) Phân vân khi chọn viết Thêm API, hay viết một API với chức năng Include
Hãy tưởng tượng chúng ta muốn xây dựng một công cụ quản lý dự án đơn giản. Chúng ta có ba mục: users, projects và các tasks. Chúng ta cũng xác định các mối quan hệ sau giữa các mục sau
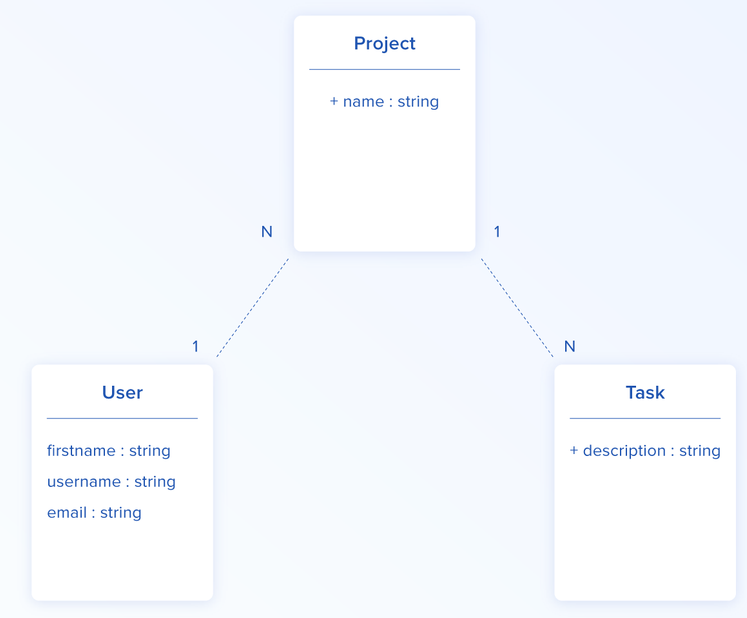
Đây là một số api mà chúng ta cần thực hiện
| Endpoint 1 | Description 2 |
|---|---|
| GET /users | list ra tất cả user |
| GET /users/:id | show user dựa vào id |
| GET /users/:id/projects | list ra tất cả project của một user |
Đầu tiên các api đơn giản, dễ đọc và có tổ chức tốt.
Mọi thứ trở nên phức tạp hơn khi request của chúng ta trở nên phức tạp.
Hãy lấy api của GET / users /: id / projects:
Tôi muốn chỉ hiển thị các tiêu đề của project trên trang chủ, nhưng các projects + task lại trên dashboard, trong khi đó không muốn thực hiện nhiều lần gọi REST-api. Tôi sẽ gọi:
GET /users/:id/projects cho trang home
GET /users/:id/projects?include=tasks (ví dụ) ở trang dashboard phía back-end trả về sẽ bao gồm tất cả các task có liên quan.
Đó là thực tế phổ biến khi thêm các query paramater ?include=... để làm việc này, và thậm chí là nó được đề xuất bởi JSON API. Các query paramater như ?include=tasks vẫn có thể đọc được, nhưng trước kia chúng kết thúc với ?include = tasks, tasks.owner, tasks.comments, tasks.comments.author
Trong trường hợp này, sẽ là khôn ngoan hơn khi tạo ra một /project endpoint để làm việc này? Một kiểu giống như / projects? userId =: id & include = tasks, hoặc là / tasks? userId =: id. Đây có thể là một sự lựa chọn thiết kế khó khăn, thậm chí còn phức tạp hơn nếu chúng ta có các mối quan hệ nhiều - nhiều.
GraphQL sử dụng include approach ở khắp mọi nơi. Điều này làm cho cú pháp để fetch các mối quan hệ trở nên mạnh mẽ và nhất quán.
Đây là một ví dụ về fetch cả các project và task từ user có id 1.
Query
{
user(id: 1) {
projects {
name
tasks {
description
}
}
}
}
Result
{
"data": {
"user": {
"projects": [
{
"name": "Migrate from REST to GraphQL",
"tasks": [
{
"description": "Read tutorial"
},
{
"description": "Start coding"
}
]
},
{
"name": "Create a blog",
"tasks": [
{
"description": "Write draft of article"
},
{
"description": "Set up blog platform"
}
]
}
]
}
}
}
Như bạn thấy, cú pháp truy vấn dễ đọc. Nếu chúng ta muốn đi sâu hơn và bao gồm các task, comments, hình ảnh và tác giả, chúng ta sẽ không nghĩ hai lần về cách tổ chức API của chúng ta. GraphQL giúp bạn dễ dàng tìm ra các object phức tạp.
c) Quản lý nhiều client khác nhau
Khi xây dựng một back-end, chúng ta luôn luôn bắt đầu bằng cách cố gắng làm cho API được sử dụng rộng rãi bởi càng nhiều clients càng tốt. Tuy nhiên, clients luôn muốn call ít hơn và fetch được nhiều dữ liệu hơn. Với deep includes, partial resources và filter, các request được tạo bởi web và mobile có thể khác nhau rất nhiều từ các các ứng dụng khác nhau
Với REST, có một vài giải pháp. Chúng ta có thể tạo một endpoint tùy chỉnh (ví dụ: một alias endpoin kiểu /mobile_user), một đại diện là (Content-Type: application / vnd.rest-app-example.com + v1 + mobile + json) hoặc thậm chí một client-specific API (như Netflix đã từng làm). Cả ba trong số chúng đều đòi hỏi phải có thêm effort từ team back-end.
GraphQL mang lại nhiều hơn cho client. Nếu client cần những request phức tạp, nó sẽ tự xây dựng các truy vấn tương ứng. Mỗi client có thể sử dụng cùng một API khác nhau.
2. Bắt đầu với GraphQL
Trong hầu hết các cuộc tranh luận về "GraphQL vs. REST" ngày nay, mọi người nghĩ rằng họ phải chọn một trong hai. Đơn giản điều đó là không đúng.
Ta hoàn toàn có thể sử dụng GraphQL trong dự án của mình như một api riêng chẳng hạn "/api/graphql"
Mục tiêu của chúng ta là tạo một endpoint /graphql mà không xoá bỏ các REST endpoint. GraphQL endpoint sẽ truy cập trực tiếp ORM để lấy dữ liệu, để nó hoàn toàn độc lập với REST logic.
Ở ví dụ này ta sẽ thực hiện với thao tác CRUD với bảng users như đã đề cập đến ở phần trên
Types
Model được trình bày trong GraphQL theo dạng type. Nên sẽ có một ánh xạ 1-1 giữa các model của bạn và các GraphQL type. User type chúng ta sẽ có dạng:
type User {
id: ID! # The "!" means required
firstname: String
lastname: String
email: String
projects: [Project] # Project is another GraphQL type
}
Queries
Query xác định những truy vấn bạn có thể chạy trên GraphQL API của bạn. Theo quy ước, cần có một RootQuery, chứa tất cả các truy vấn hiện có. Ta sẽ chỉ ra truy vấn trong REST tương đương của mỗi query dưới đây:
type RootQuery {
user(id: ID): User # Tương ứng với GET /api/users/:id
users: [User] # Tương ứng với GET /api/users
project(id: ID!): Project # Tương ứng với GET /api/projects/:id
projects: [Project] # Tương ứng với GET /api/projects
task(id: ID!): Task # Tương ứng với GET /api/tasks/:id
tasks: [Task] # Tương ứng với GET /api/tasks
}
Mutations
Nếu truy vấn là request GET, mutations có thể được xem như POST / PATCH / PUT / DELETE request (mặc dù thực sự chúng là các phiên bản đồng bộ của các query).
Theo quy ước, chúng ta đưa tất cả các mutations của chúng ta vào RootMutation:
type RootMutation {
createUser(input: UserInput!): User # Tương ứng với POST /api/users
updateUser(id: ID!, input: UserInput!): User # Tương ứng với PATCH /api/users
removeUser(id: ID!): User # Tương ứng với DELETE /api/users
createProject(input: ProjectInput!): Project
updateProject(id: ID!, input: ProjectInput!): Project
removeProject(id: ID!): Project
createTask(input: TaskInput!): Task
updateTask(id: ID!, input: TaskInput!): Task
removeTask(id: ID!): Task
}
Lưu ý rằng chúng ta giới thiệu các type ở đây, được gọi là UserInput, ProjectInput, và TaskInput. Đây cũng là một điều phổ với REST, để tạo ra một input data để create và update resource. Ở đây, UserInput type của chúng ta là User type mà không có các trường id và projects, và từ khoá input thay thế cho type:
input UserInput {
firstname: String
lastname: String
email: String
}
Schema
schema {
query: RootQuery
mutation: RootMutation
}
Resolvers
Bây giờ chúng ta có public schema, đã đến lúc phải nói cho GraphQL biết phải làm gì khi mỗi queries/mutations được request
Ví dụ:
const models = sequelize.models;
RootQuery: {
user (root, { id }, context) {
return models.User.findById(id, context);
},
users (root, args, context) {
return models.User.findAll({}, context);
},
// Resolvers for Project and Task go here
},
/* For reminder, our RootQuery type was:
type RootQuery {
user(id: ID): User
users: [User]
# Other queries
}
Điều này có nghĩa là, nếu truy vấn user (id: ID!)được request trên GraphQL, thì chúng ta sẽ trả về User.findById (), là một Sequelize ORM function , từ database.
Còn về việc join các model khác trong request? Vâng, chúng ta cần phải định nghĩa nhiều resolvers hơn:
User: {
projects (user) {
return user.getProjects(); // getProjects is a function managed by Sequelize ORM
}
},
/* For reminder, our User type was:
type User {
projects: [Project] # We defined a resolver above for this field
# ...other fields
}
Vì vậy, khi chúng ta request projects field trong một User type ở GraphQL, join này sẽ được append vào database query.
Cuối cùng, resolvers cho mutation:
RootMutation: {
createUser (root, { input }, context) {
return models.User.create(input, context);
},
updateUser (root, { id, input }, context) {
return models.User.update(input, { ...context, where: { id } });
},
removeUser (root, { id }, context) {
return models.User.destroy(input, { ...context, where: { id } });
},
// ... Resolvers for Project and Task go here
}
trên đây là mã giả trình bày cách hoạt động của graphQL , để xem chi tiết bạn có thể tham khảo ở repo sau : https://github.com/amaurymartiny/graphql-example
3 Một số vấn đề khi sử dụng GraphQL
GraphQL thực sự có rất nhiều lợi ích, tuy nhiên nó cũng có rất nhiều thách thức cần các lập trình viên xử lý
3.1 Bài toán N + 1.
Cùng xem xét lại ví dụ trước đó:
{
users {
projects {
name
tasks {
description
}
}
}
}
Giả xử trong trường hợp này nếu ta thực hiện lấy ra danh sách user cùng với các project đi cùng ta sẽ gặp một vấn đề với resolver sau
users (root, args, context) {
return models.User.findAll({}, context);
},
Ở resolver này nếu sử dụng một orm đủ tốt để có thể lấy projects đi kèm thì nó sẽ là một câu join, tuy nhiên hầu hết hiện tại là thực hiện query project sau đó gắn vào đối tượng user.
việc này dẫn đến phát sinh việc ta gọi quá nhiều câu query lên database chỉ để lấy được danh sách user.
Vì vậy giải pháp được xử dụng ở đây có thể là cache mememory hoặc sử dụng một context nâng cao của graphQL (data loader). 2 cách này thực sự không phải là đơn giản
Và đối với các lập trình viên .Net lâu năm thì khi đọc GraphQL họ sẽ nghĩ ngay tới OData, ngoài ra cũng có một số thư viện dành cho các ngôn ngữ khác. Trong khi đối với graph , do là trend mới thì hầu như bạn phải tự implement cách truy vấn dữ liệu
Tuy nhiên thì IDTEK cũng có cách xử lý riêng của mình (cái này sẽ được trình bày ở phần sau hehe :D)
3.2 Vấn đề Security
Việc chúng ta cho client nắm được cấu trúc dữ liệu ở phía backend và chủ động việc lấy dữ liệu cần lấy thì vấn đề liên quan đến bảo mật cũng rất nhiều thách thức và rủi ro.
Maximum Query Depth - Độ sâu đỉnh truy cập tài nguyên
query IAmEvil {
author(id: "abc") {
posts {
author {
posts {
author {
posts {
author {
# that could go on as deep as the client wants!
}
}
}
}
}
}
}
}
Thử tượng tượng một cuộc tấn công Access Denial Service xảy ra, với một cấu trúc query động từ model này đi đến các model khác, hoàn toàn có thể làm server lộ ra những dữ liệu nhạy cảm, không chỉ là đơn giản quá tải server.
Vì vậy ta cần chức năng giới hạn độ sâu của câu truy vấn GraphQL nhằm tránh quá tải server
Authorization (Phân quyền người dùng)
Việc phân quyền người dùng đối với từng enpoint cũng thực sự nhiều thách thức.
chẳng hạn đơn giản đối với câu query sau
query {
user {
chatGroup {
users: {
name,
contact,
creditCardNumber,
phoneNumber,
passWordHash
}
}
}
}
Nhìn vào thì các bạn hẳn sẽ biết rủi ro thế nào nếu user lấy được thông tin nhạy cảm của những người dùng cùng chung nhóm.
Vì vậy thì cách để ta ngăn cản effort brute force data đó chính là giới hạn các trường thông tin được lấy đối với user trên hành động này.
Mà việc này thì chưa bao giờ dễ dàng cả
GraphQL will make some tasks more complex (Việc sử dụng GraphQL đôi khi gây ra một số task không nên có và thêm phức tạp khi tái cấu trúc)
Khi định nghĩa một GraphQL Server bạn cần các bước
Định nghĩa
- Types
- Queries
- Mutators
- Resolvers
Trong khi một model của một ORM đã thể hiện đầy đủ tính chất của một bảng trong database, ta vẫn phải định nghĩa thêm Type cho Model ở GraphQL thì một bước hơi thủ công và tốn thời gian
Ngoài ra việc mỗi client một kiểu truy vấn khác nhau sẽ làm phân tán code của bạn nhiều hơn , dẫn đến refactor cấu trúc dữ liệu trở nên mất nhiều thời gian hơn
4. Kết luận
Nói tóm lại việc sử dụng GraphQL cũng có những mặt lợi và những mặt hại của nó.
Lợi ích có thể kể đến như lập trình viên frontend có thể nắm được rõ cấu trúc dữ liệu và thực hiện thao tác với dữ liệu (CRUD) một cách dễ dàng. Không cần phải chờ từ phía lập trình viên backend.
Việc truy vấn một cấu trúc dữ liệu (Strong Type Data Model) cố định được trả về giúp giảm thiểu lỗi ở frontend.
Ngoài ra thì còn số một số mặt lợi đã giới thiệu ở phần đầu.
Vậy nên GraphQL theo khảo sát thường được sử dụng trong trường hợp sau:
- Rất thích hợp khi mà product của bạn có các clients cần flexible response format, lúc thì cần như thế này, lúc cần như thế kia mà không cần backend phải thay đổi.
- Sản phẩm hướng đến cộng đồng (Dữ liệu không nhạy cảm nhiều, tốc độ phát triển nhanh, không đòi hỏi tính nhất quán của dữ liệu cao)
--> Đối với IDTEK hiện tại sau thời gian thử dụng 1 năm thì một số vấn đề cơ bản cũng được giải quyết . Tuy nhiên với tính chất phát triển dự án giải pháp doanh nghiệp . Do yêu cầu nghiệp vụ thay đổi liên tục, dữ liệu đòi hỏi tính chặt chẽ cao, và hơn hết là không cần yêu cầu quá khắt khe về network performance (băng thông dữ liệu). Thì việc sử dụng graphQL đã không tạo ra được nhiều ưu điểm như mong muốn.
Tuy nhiên đối với một số dữ liệu dạng metadata, category thì việc sử dụng graphql tỏ ra khá hữu hiệu. Rút ngắn thời gian phát triển.
Trong tương lai thì IDTEK vẫn sẽ tiếp tục sử dụng công nghệ GraphQL đi cùng với REST API , song song là nghiên cứu và phát triển lõi GraphQL để dễ dàng đồng hành cùng lập trình viên trong quá trình phát triển. Và hướng đến phục vụ các Product Software trong tương lai
Dưới đây là một số feature mà IDTEK đã phát triển được
http://readme.idtek.com.vn/RBCtTMEBQi-1snXW1R7h_g
Ngoài ra hiện tại một số framework dành cho GraphQL đã được phát triển với nhiều tính năng như
Apolo GraphQL Server : https://www.apollographql.com/
GraphCool Server : https://www.graph.cool/
Các framework này nhận được sự phản hồi rất tích cực từ cộng đồng mã nguồn mở cho nên theo mình GraphQL vẫn là một xu hướng rất đáng để nghiên cứu và phát triển trong nhiều năm tới.
Tài liệu tham khảo
https://graphql.org/learn/
https://techblog.vn/graphql-vs-rest-a-graphql-tutorial
https://www.howtographql.com/
https://blog.logrocket.com/5-reasons-you-shouldnt-be-using-graphql-61c7846e7ed3/
https://graphql-dotnet.github.io/docs/getting-started/introduction/


Thảo luận